Like many websites FT.com is not a single application but a collection of microservices and as you browse the site you’re likely to cross between several independent applications. This raises challenges for delivering the front-end because we need to make sure that this experience is seamless and we maintain a consistent interface.
When we rebuilt the site in 2015 we created a shared UI module which provided the global user interface, commonly used components, and all sorts of other useful bits. This module ensured our services maintained a high level of consistency but it wasn’t very efficient because it required our users to redownload the same assets over and over again as they moved around the site.
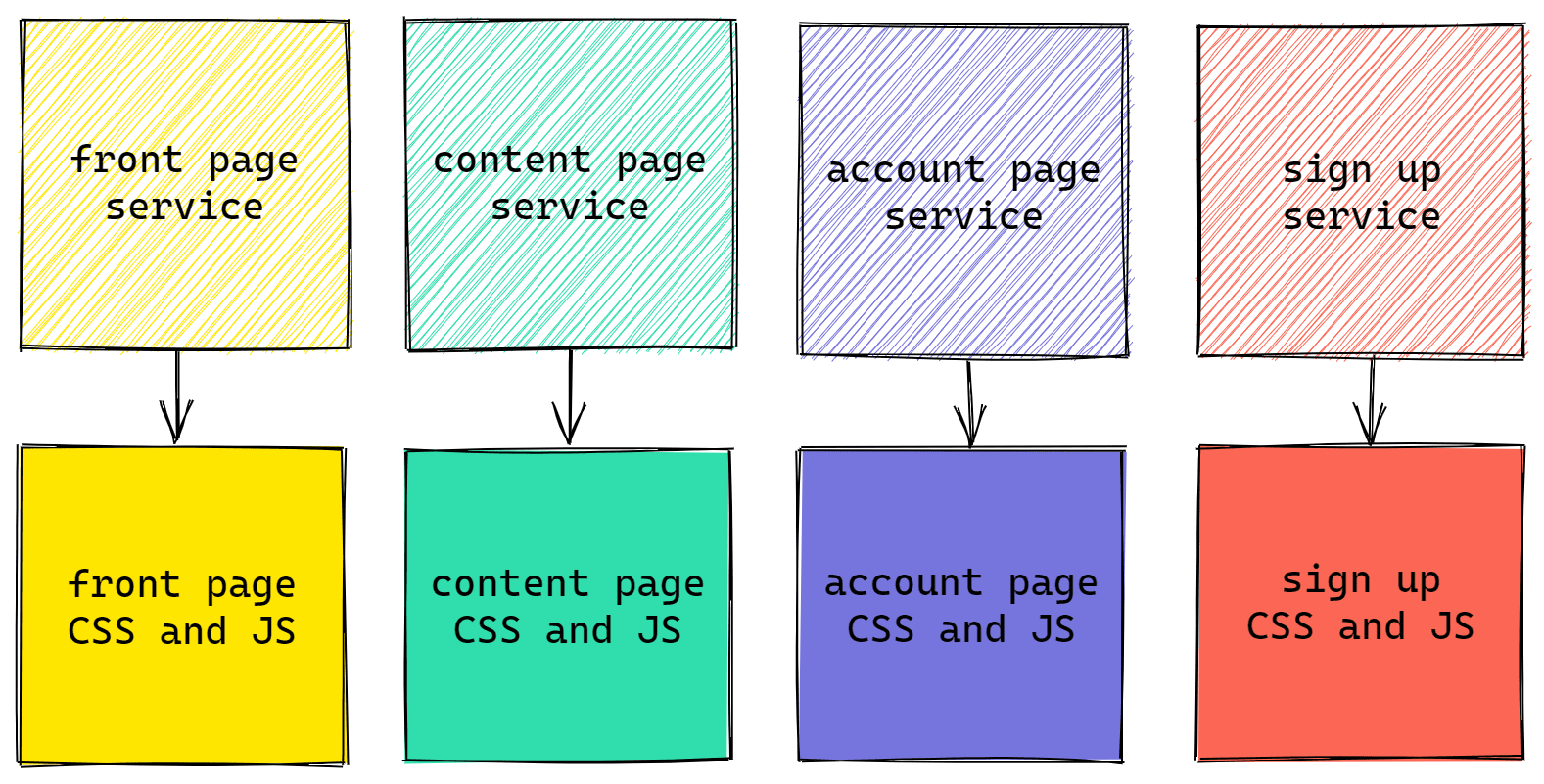
We knew this wasn’t good for performance so we started shipping precompiled bundles of code with our shared UI module and instructed our services to exclude anything they could reuse from them. After this change around 25% of the JavaScript needed by FT.com could be downloaded once and not fetched again as you browsed the website - a big win considering the cost of JavaScript!
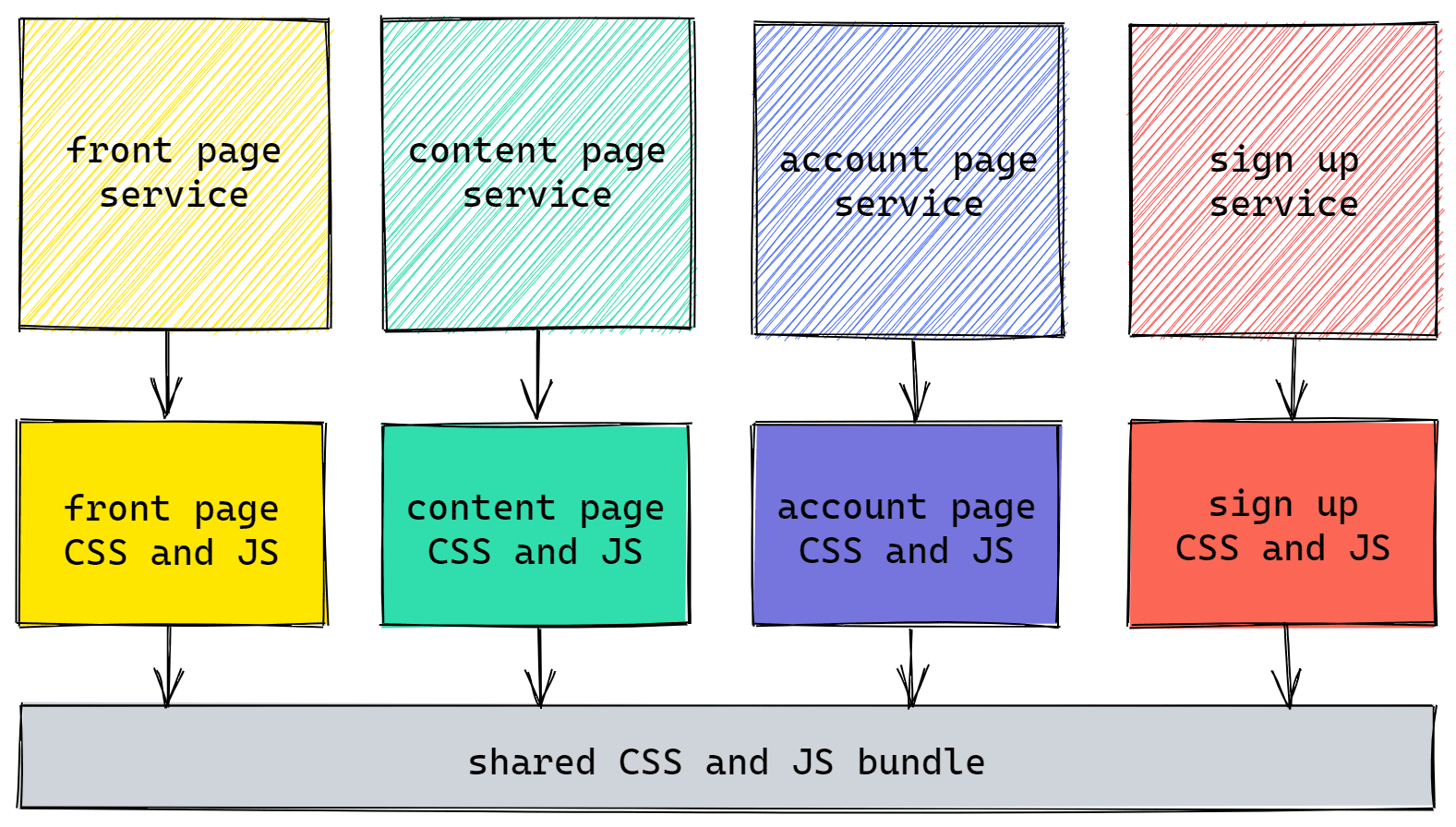
Whilst this strategy was good it wasn’t perfect; it meant pushing code that was not always needed, it could be tricky to work with locally, it was an occasional single point of failure (not very microservices!), and we bust the cache regularly - forcing our users to redownload everything again anyway.
When we rebuilt the front-end toolset for FT.com last year we wanted to avoid all of these pitfalls. Our plan was to enable our services to share as much client-side code as possible whilst also improving the developer experience, remove any single point of failure, and allow our users to cache the assets they download for longer.
To achieve all of these things we decided to split up the client-side CSS and JS that our services compiled into lots of separate pieces and deploy them all to the same place. Our theory was that this would create a pool of shared resources that any service could call upon.
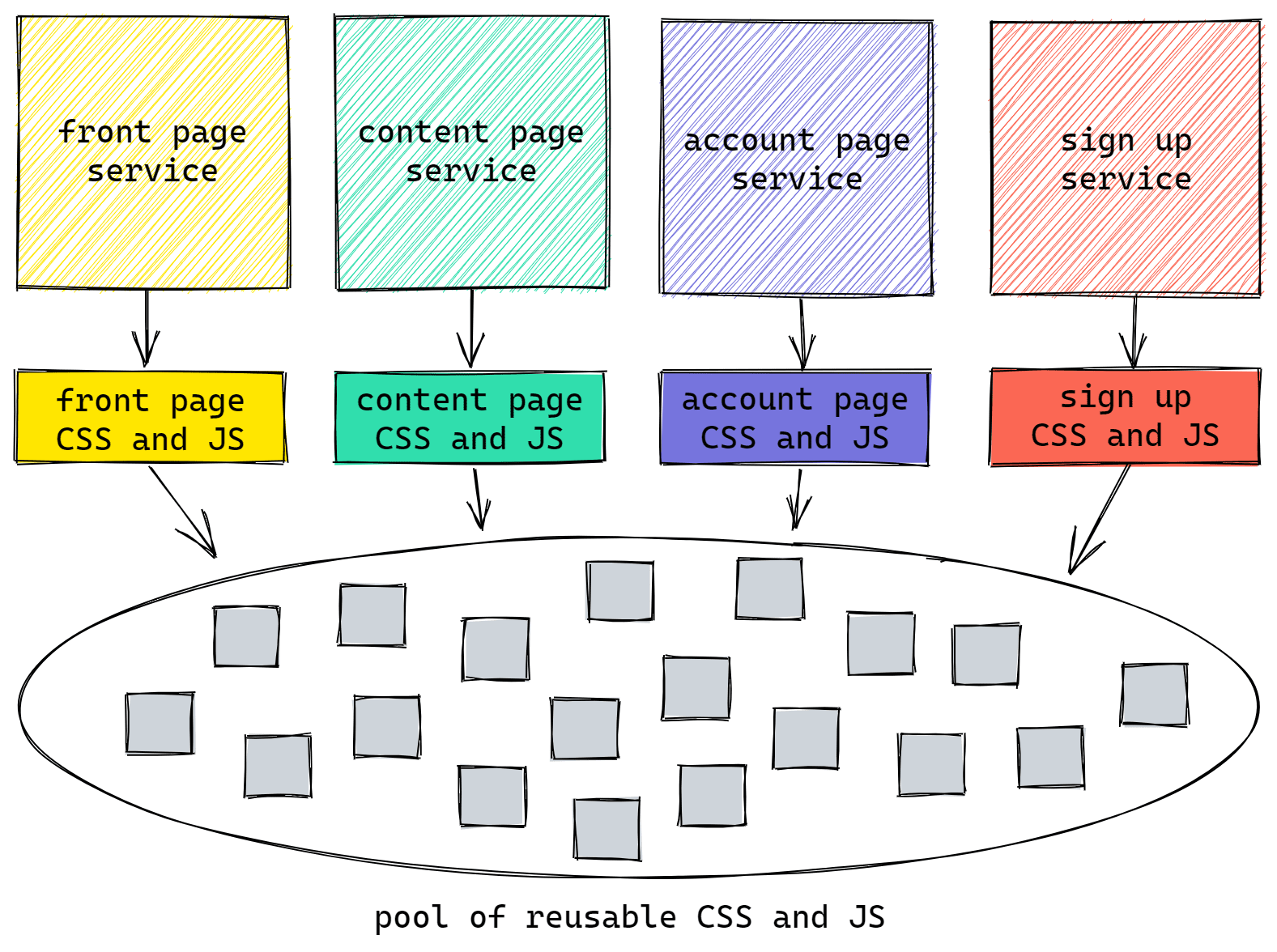
All we had to do to implement this strategy was make sure that our services compiled the same assets with the same names. How hard could that be?
Code splitting
The first concept we needed to learn was how to use code splitting effectively. In short, code splitting enables you to break apart one big bundle of code into smaller chunks.
Bundling up code only to break it apart again sounds strange but it’s a useful tool for minimising cache invalidation (e.g. separating code that changes often from code which changes less often) and loading code only when it’s needed (e.g. loading a component only when it is scrolled into view.)
Most popular JavaScript bundlers support dynamic code splitting by using the import() function but we couldn’t rewrite all of our services and their many dependencies to use dynamic imports. Our only option was to utilise Webpack because it’s currently the only bundler which supports a configuration based method for code splitting that we could centralise and share.
After configuring our code splitting rules I thought we were done.
The problem
In August last year we started shipping Page Kit, our new front-end toolset, and after celebrating the first few migrations going live I decided to check how our plan was going.
Shit!
The only code our Page Kit powered services were sharing was the tiny Webpack runtime (about 2kb) and nothing else! Although the services had all generated chunks with the same names as we had planned they had not created them with the same content hash:
| Service A | Service B | Matches? |
|---|---|---|
| webpack-runtime.53ab.js | webpack-runtime.53ab.js | ✅ |
| o-header.48cb.js | o-header.5ea8.js | ❌ |
| o-footer.82b8.js | o-footer.bca3.js | ❌ |
| o-tabs.c77f.js | o-tabs.c7e7.js | ❌ |
I hurriedly downloaded and unminified a few files to see what the differences between them could be. Across the files I looked at there appeared to be only one small but repeated difference: the module IDs did not match.
What are Module IDs?
When Webpack builds the dependency graph for your project it gives each file, or module, it finds a unique ID. Before outputting your JavaScript bundles Webpack will replace every import statement and require() call in your source code with its own mechanism for resolving the modules at runtime which uses these IDs. For example, import React from "react" could become var React = __webpack_require__("ID").
By default when Webpack is run in development mode a module’s ID will be its relative path on disk (e.g. ./src/utilities.js or ./node_modules/react/index.js) but using paths means that the IDs can get quite long, may vary between users and project installs, and possibly even reveal something they shouldn’t, so in production mode Webpack uses simple numerical values instead. This value is assigned incrementally, so the first module added to the dependency graph will have an ID of 1, the second 2, etc.
The reason why our modules had different IDs is because the order they are found and added to the dependency graph is different for each service.
Fortunately, Webpack allows you to choose which module ID algorithm to use or even provide your own (which we did.) With the module ID problem now sorted I tested again.
Nope!
The services I tested were now compiling a few matching chunks but the majority still had different hashes despite now mostly having the same content inside.
What is a content hash?
Webpack makes adding hashes to your file names very easy, you only need to add a [contenthash] placeholder to your output filename and a hash will magically appear in its place when the file is written.
I had long assumed that Webpack’s content hashes were like a file verification checksum but the struggle we were having showed that this assumption must be wrong. Searching GitHub and Google I only found more confusion so I started digging into Webpack’s source code to find answers. From this I discovered:
- Each chunk’s content hash is created by combining some metadata about the chunk, the chunk’s ID, and the hashes of all the modules it contains…
- Each module also has a hash. How this is generated varies between the different types of module but they’re mostly some combination of the module’s ID, the IDs of its dependencies, the original source file contents, and a list of its used exports.
Equipped with this new knowledge I tapped into Webpack using its compilation hooks to log information about the modules contained in the mismatched chunks.
Ah-ha!
Skimming through the long list of differences between the logs I could see that it was the lists of used exports which were not always the same.
What are used exports?
When a JavaScript module is added to the dependency graph Webpack will create a list of the properties it exports and each time that module is imported it will try to track which of those properties gets used (it’s this clever feature that enables tree shaking by “pruning” any unused properties.)
The reason this was affecting our content hashes was because our services do not all use their dependencies in the same way.
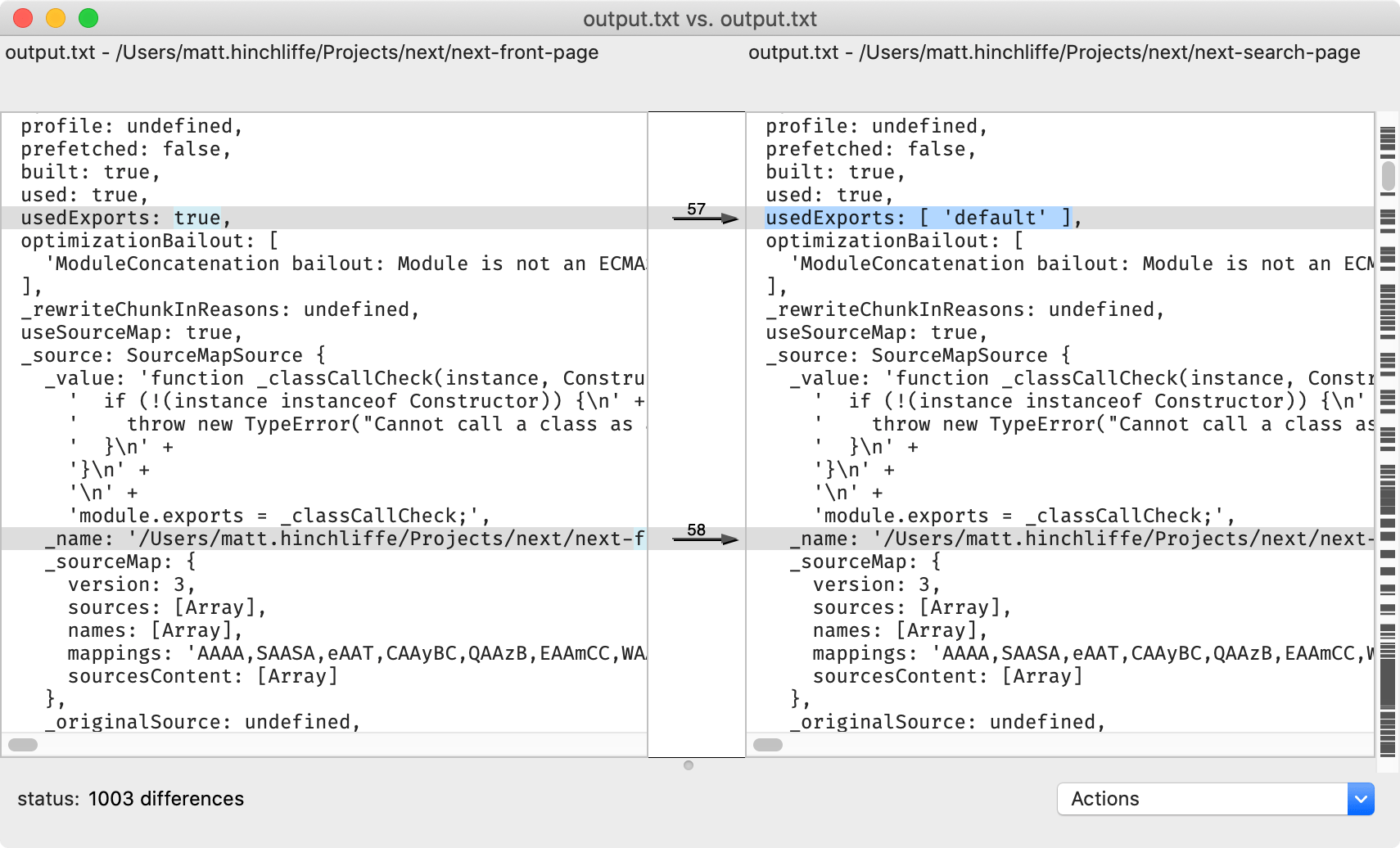
By comparing logs of module metadata I could find the differences between services.
Solving this was tricky because we wanted to allow tree shaking in our non-reusable code but disable it in any code which could be reused. Webpack does not currently allow this level of control via an option but it is possible via a plugin so I hacked one together. Feeling confident that the used exports problem was now fixed I tested once more.
Arghh!
Now we had a few more matching chunks than before but half of them still had different hashes. The contents of reusable chunks looked identical so I used my logging plugin again to find out what the differences could be and I eventually found where to look.
What is @babel/runtime?
We use Babel to compile the modern JavaScript and syntax extensions we use in our source code into plain ES5 which can be run by all of the browsers we support. For some transformations helper functions (e.g. to merge two objects) may be imported from a package called @babel/runtime. By default the code for these helpers will be injected into every module which needs them but to avoid duplication Babel can also be configured to import them from an external package instead, which we had done.
Just like the previous problems which helper functions are needed and how they are used varies between our services and because they’re so widely depended upon and near the root of our dependency graph this was causing a cascade of content hash changes that spread throughout.
To resolve this we chose to disable the use of the external @babel/runtime package. Injecting the helpers into the modules was not only simpler but the difference in code size was negligible (~1-3kb in total) and because the JavaScript optimiser is so clever now this change also meant hundreds of function calls could actually be cleaned away!
Conclusion
The services that make up FT.com can now often share and reuse the majority of the JavaScript they compile - in some cases over 90%. We don’t currently know the impact this has had on site-wide performance nor user behaviour so we don’t actually know if it was worth it but our working theory is that we did a good thing.
Our simple idea became a tough battle (and I haven’t documented the real frustration, missteps, and blind luck) but I hope that the next version of Webpack will remove the need for many of the workarounds we had to find and implement. Webpack 5 has new algorithms for module hashes, a proper API for disabling tree shaking on modules, and module federation could supersede all of this, albeit with challenges of its own.

Thank you to Maggie Allen and Rhys Evans for proofreading this article 🙇♂️