How does FT.com make nearly a million articles available to apps which serve 40 million page views a month? The answer to that is of course very long and quite complex but if you dig down a few layers I can tell you that you’ll eventually find that the content is all stored in two (fairly small) Elasticsearch clusters. So how do all of the articles get into those clusters? An old, imperfect and somewhat inefficient system that just keeps chugging away.
For redundancy and performance the FT.com team pushes all the content for the website into two Elasticsearch clusters, one in North America and one in Europe. Each one is tended to by a Node.js application which processes content and pushes the results into the cluster. The applications receive notifications when content changes, continuously refresh the content in the cluster, and provide a web interface for any manual operations.
The clusters and their tending apps run independently and they are (almost) completely unaware of each other’s existence!
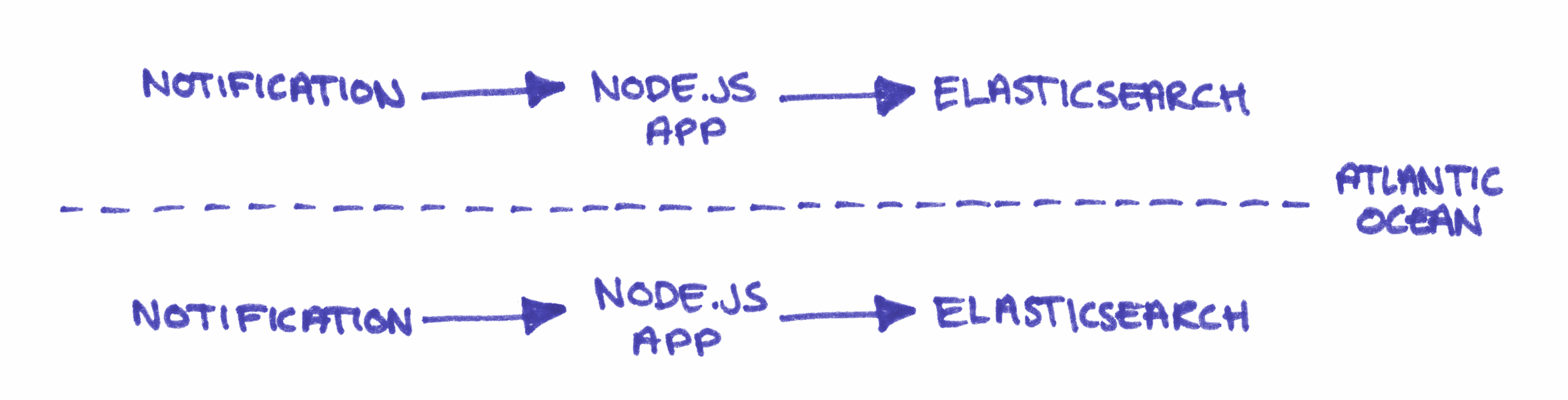
Having totally unconnected data stores and content processing means that the team relies on eventual consistency but without any guarantee of it. This made me feel a bit uncomfortable for a long time; wouldn’t it be better if we could be sure visitors got the same experience on either side of the Atlantic?
The independent systems also mean a lot of work is repeated as every article must be processed twice - once in each location - and I can tell you that processing an article is quite a complicated thing! Every piece of content is assembled from a web of separate resources and some of those resources can change at any time or could fail to be resolved. If only we could process notifications and reprocess old content once instead of twice then we could save a lot of effort and increase consistency, right?
An improved architecture might include a message queue at the front of it, so that each app can can pick up a single notification, process that and then deliver the result to both Elasticsearch clusters in unison. This architecture could offer the same level of redundancy but do less work and provide a higher level of confidence that the content is the same in both places.
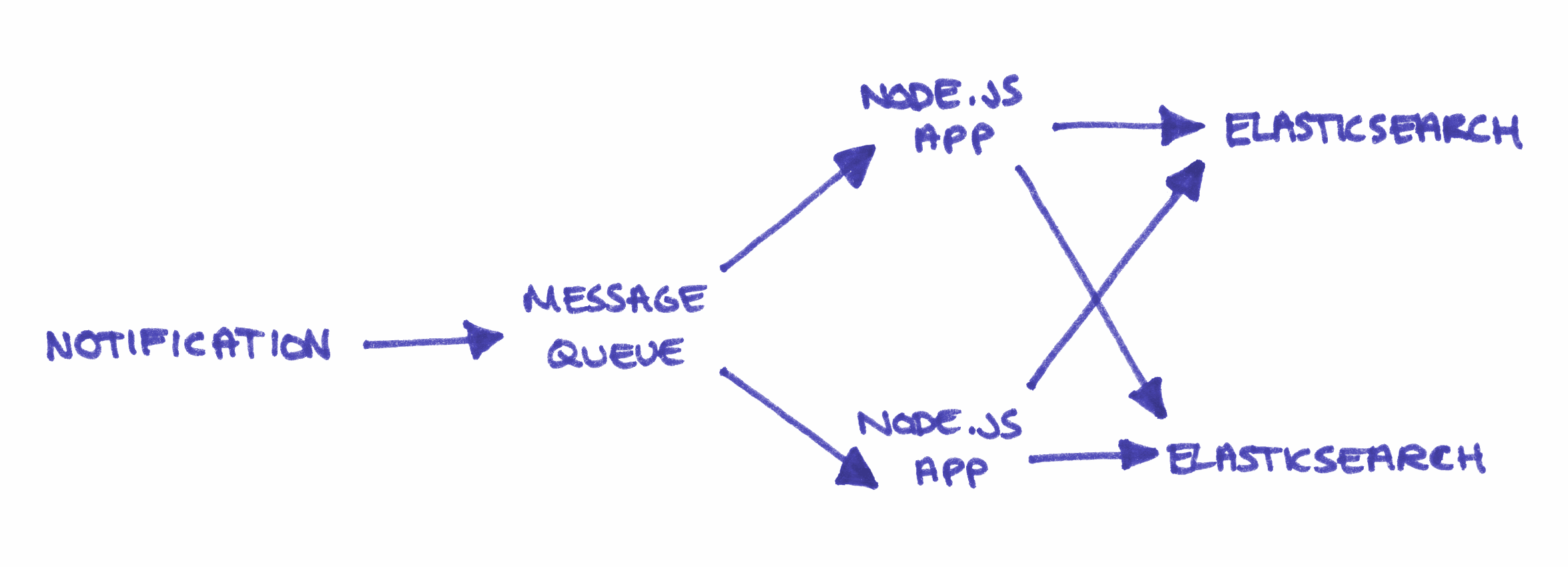
I argued to change the architecture a few times, so why haven’t any changes ever been made?
Because I couldn’t make a business case for it.
The current system has now been running for 6 years and in that time it has processed literally billions of articles with a reliability rate of several-nines. If an article fails to make it into one of the clusters then a simple health check will detect the differing counts and automatically try to fix it. If the automated check cannot resolve the problem then the team will be alerted to the discrepancy and the different content can be fixed manually using the web interface. If this still doesn’t work then a developer or a colleague in support can consult the app’s logs to work out what to do next.
What we built years ago still works very reliably and when it does occasionally go wrong then the steps to diagnose and resolve issues are easy to follow and rationalise. So much so that developers often don’t need to get involved at all.
It doesn’t matter much to the business if I think it’s architecturally inferior because investing in “correcting” the system would offer no measurable improvement. In fact, changing things would add more complexity to configuration and debugging and adding another thing to the stack would only increase costs and maintenance.
So it’s just fine the way it is.